
When you drag a Copy activity into the pipeline editor canvas, you will see the properties of that activity. Then, when you click the Source tab, you will see something similar to Figure 3.57. Notice that the value shown in the Source Dataset drop‐down box is the one you created in Exercise 3.9.
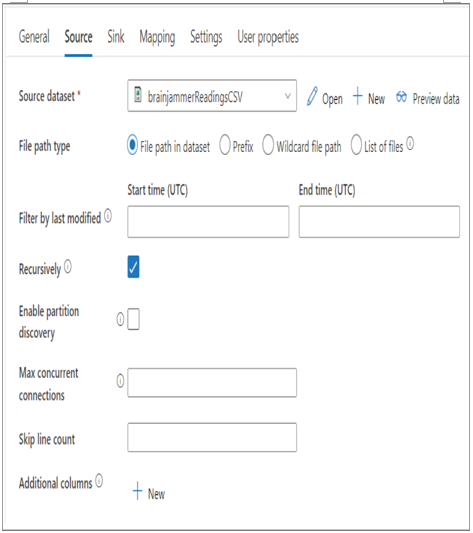
FIGUER 3.57 Azure Synapse Analytics Pipeline Copy data Source tab
Clicking the Preview Data link will open a window that contains 10 rows from the targeted data source of the integration dataset. To view the details of the brainjammerReadingsCSV integrated dataset, select the Open link. This integration dataset is mapped to a CSV file residing on an Azure Files share. In Exercise 3.9 you were instructed to target a specific file, but as you see in Figure 3.57, it is also possible to pull from that share based on the file prefix or a wildcard path, or select a list of files.
SINK
Chapter 2 introduced sink tables. A sink table is a table that can store data as you copy it into your data lake or data warehouse.
You have not completed an exercise for the integrated dataset you see in the sink dataset shown in Figure 3.58. The integration dataset is of type Azure Synapse dedicated SQL pool and targets the ALL_SCENARIO_ELECTRODE_FREQUENCY_VALUE table you created in Exercise 3.7. The support file BrainjammerSqlPoolTable_support_GitHub.zip for this integration dataset is located in the Chapter03 directory on GitHub at https://github.com/benperk/ADE. The most interesting part of the Sink tab is the Copy method options: Copy Command, PolyBase, Bulk Insert, and Upsert. Support files are discussed in the upcoming sections.
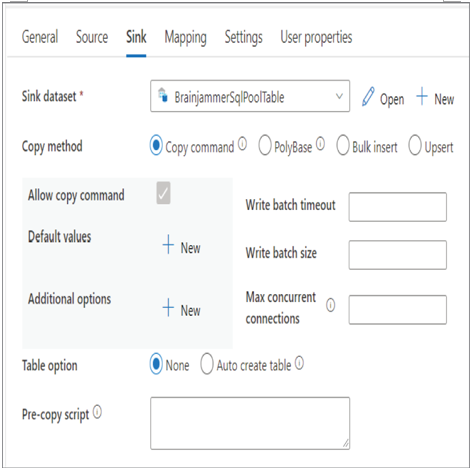
FIGUER 3.58 Azure Synapse Analytics Pipeline Copy data Sink tab
When you select the Copy Command option, the source data is placed into the destination using the COPY INTO SQL command. When you select the PolyBase option, some of the parameters on the tab change, specifically values like Reject Type and Reject Value, which were introduced in Chapter 2. Note that you will achieve the best performance using either Copy Command or PolyBase. Choosing the Bulk Insert option results in the Copy command using the BULK INSERT SQL command. UPSERT is a new command and is a combination of INSERT and UPDATE. If you attempt to INSERT a row of data into a relational database table that already has a row matching the primary key, an error is rendered. In the same manner, if you attempt to UPDATE a row and the primary key or matching where criteria do not exist, an error will be rendered. To avoid such errors, use the UPSERT statement, which will perform an INSERT if the row does not already exist and an UPDATE if it does.