
The Mapping tab, as shown in Figure 3.59, provides a comparison of the source data to the target data structure.
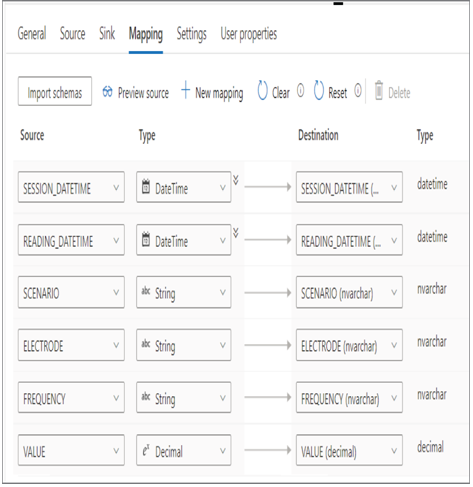
FIGUER 3.59 Azure Synapse Analytics Pipeline Copy data Mapping tab
You have the option to change the data order, the column name, and the data type. This is a very powerful feature that can prevent or reduce issues when performing a copy—for example, having extra or missing columns and wrong data type mapping, or trying to place a string into a numeric or datetime column.
Copy Data Tool
The Copy Data tool is a wizard that walks you through the configuration and scheduling of a process to copy data into your workspace. The first window offers numerous scheduling capabilities like Run Once Now, Schedule, and Tumbling. The Run Once Now option does exactly what its name implies. The Schedule option offers the configuration of a start date, a recurrence, like hourly, daily, weekly, etc., and an optional end date. Tumbling, like the similar option discussed previously regarding triggers, has some advanced capabilities like retry policies, concurrency capabilities, and delaying the start of a run.
The copy retrieves data from a datastore connection from the set of integration datasets configured for the workspace. The destination can be, for example, a SQL pool running on the Azure Synapse Analytics workspace. Before the Copy Data tool configuration is executed, you might see something similar to Figure 3.60.
There is a step called Mapping where the wizard analyzes the source data schema and attempts to map it to the destination data schema. If there are any errors, you are prompted to repair them, which is quite a powerful and helpful feature.
Import Resources from Support File
You can find an example of a support file (BrainjammerSqlPoolTable_support_GitHub.zip) in the Chapter03 folder on GitHub at https://github.com/benperk/ADE. This compressed file contains information about the configuration of an integration dataset. If you want to include this configuration in your Azure Synapse Analytics workspace, you would use this feature to import it. Note that the configuration contains some sensitive information, so do not make this support file public. The example on GitHub has been modified to remove the sensitive information.
FIGUER 3.60 Azure Synapse Analytics Copy Data tool
Import from Pipeline Template
You may have noticed the Save As Template option in Figure 3.56. There is also an Export Template option. Export templates are accessible by clicking the ellipse (…) on the right side of the page, which renders a drop‐down menu. If your Azure Synapse workspace is configured with a source control, like what you did in Exercise 3.6, then each time you click the Commit button, the configuration is saved or updated into that repository. Any time you want to import that pipeline template, you can download it from your source control, or you can use an exported or saved template from another source.
Azure Data Factory
It is the near to midterm objective of Microsoft to merge as many features as possible from all existing data analytics offerings into Azure Synapse Analytics. Looking back at Figure 1.17 and Figure 1.21, you can the similarities between Azure Synapse Analytics and Azure Data Factory. Both products use the same procedures, configuration, and requirements for creating linked services, integration datasets, and pipelines. Two primary differences between Azure Synapse Analytics and Azure Data Factory concern SSIS packages and the term Power Query. Azure Data Factory now fully supports importing and running existing SSIS packages—refer to Figure 3.37, which shows the capability as Azure‐SSIS preview. The feature is currently in the Azure Synapse Analytics workspace but not yet fully supported. Until it is fully supported in Azure Synapse Analytics and no longer in preview mode, I recommended using the SSIS capability of Azure Data Factory for production workloads. Complete Exercise 3.10 to provision an Azure data factory.