
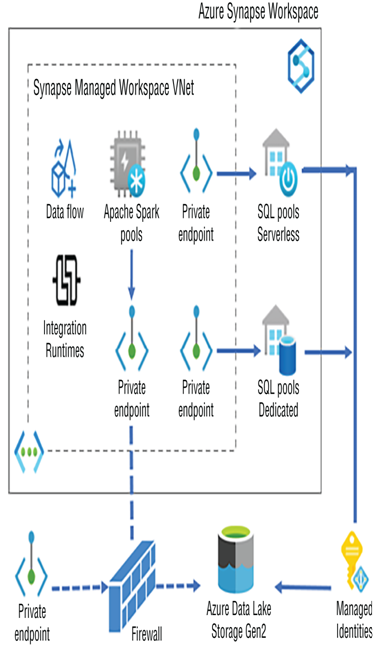
In Exercise 3.3 you enabled managed virtual networking during the provisioning of the Azure Synapse Analytics workspace. This feature enables you to configure outbound workspace connectivity with products, applications, and other services that exist outside of the managed virtual network. When you click the Managed Private Endpoints link, you will see some existing private endpoints. As shown in Figure 3.41, the managed VNet contains data flow, integration runtimes, Spark pools, and those private endpoints.
Private endpoints provide connectivity not only with Azure products but also with on‐premises applications and services offered by other cloud hosting providers. Another conclusion you can get from Figure 3.41 is that both serverless and dedicated SQL pools have globally accessible endpoints, whereas Spark pools do not. That means client applications and consumers like Power BI can make a direct connection to the SQL pools to extract data but cannot do so from a Spark pool. Azure Synapse compute pools have access to the ADLS, which is configured when you first provision the Azure Synapse Analytics workspace. The Spark pool uses a private endpoint to make the connection, while the SQL pools use an ADLS endpoint, similar to the following.
Finally, the ADLS can and should have a firewall configured to restrict access to the data contained within it. Especially for production and/or private data, consider having a firewall. Chapter 8 discusses firewalls in more detail.
FIGUER 3.41 Azure Synapse Analytics private endpoints
Code Libraries
By default, Azure Synapse Spark pools come with numerous components and code libraries. As shown in Figure 3.30, components like Java 1.8.0_282, .NET Core 3.1, Python 3.8, and many others are preinstalled on the pool instance(s) for usage in your data analysis and transformation procedures. In addition, you can use more than 100 preinstalled libraries—for example, numpy 1.19.4, pandas 1.2.3, and tensorflow 2.8.0. If you find that a library is missing, you can upload the code package to the platform and use it. In addition to using third‐party packages, you can code your own set of data transformation logic, build the package, upload it to the platform, and use it.
There are three scopes where you can make packages available: session, pool, and workspace. At least one is required. When you add a new package to your environment without testing, you are taking a risk. The new package may have some impact on the current ongoing processing pipeline workflows. If you do not have another testing‐oriented environment for determining the impact of changes, then consider constraining an uploaded package to a session, instead of the pool or workspace. When you give the code package (aka library) the scope of pool, it means all the instances of that provisioned pool will include the package, while a package with the workspace scope applies the code library on all pools in the Azure Synapse Analytics workspace. Read more about workspace packages in the next section.
WORKSPACE PACKAGES
The best way to learn more about workspace packages is by performing an exercise. In Exercise 3.5 you will upload a simple Python package to the Azure Synapse Analytics workspace and execute it. The source code for the package can be found in the Chapter03/Ch03Ex05/csharpguitar directory on GitHub here at https://github.com/benperk/ADE.