
The Manage hub includes the enablers to provision, configure, and connect many Azure Synapse Analytics features to other products. From the creation of SQL pools to the configuration of GitHub, read on to learn about each possibility.
Analytics Pools
When you run a SQL script in Azure Synapse Analytics Studio, some form of compute machine is required to perform its execution. Those machines are called pools and come in two forms: SQL and Spark. You should provision a SQL pool if you are working primarily with relational databases, and a Spark pool if you are working primarily with files. It is perfectly reasonable that your data analytics solution span across both of those scenarios, i.e., relational databases and files. If this is the case, you can provision both types of pools and use them as required to transform, analyze, and store data. You will need to find the optimal configuration for your given scenario.
SQL POOLS
By default, when you provision Azure Synapse Analytics, a serverless SQL pool is provided. Creating a dedicated SQL pool is rather simple: Click the + New link (refer to Figure 3.27) and provide the necessary information, as shown in Figure 3.28. Remember that dedicated SQL pools were previously referred to as Azure SQL data warehouses.
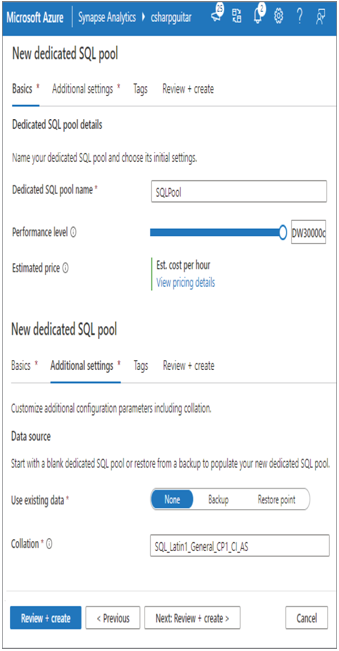
FIGUER 3.28 Creating an Azure Synapse Analytics dedicated SQL pool
Table 3.7 summarizes the numerous differences between dedicated and serverless SQL pools.
TABLE 3.7 Dedicated vs. serverless SQL pools
| Capability | Dedicated SQL pool | Serverless SQL pool |
| Database tables | Yes | No |
| External tables (CETAS) | Yes | Yes |
| Triggers | Yes | No |
| Materialized views | Yes | No |
| DDL statements | Yes | Views and security only |
| DML statements | Yes | No |
| Azure AD integration | Yes | Yes |
| Views | Yes | Yes |
| Stored procedures | Yes | Yes |
| Select performance level | Yes | No |
| Max query duration | No | Yes, 30 minutes |
The most obvious constraint when running on a serverless SQL pool is that you cannot create tables to store data on. When using a serverless pool, you should instead consider using external tables. In Chapter 2 you learned how to create an external table. That process requires the creation of a data source, using CREATE EXTERNAL DATA SOURCE, that identifies the file(s) containing the data you want to query. Then you identify the file format using CREATE EXTERNAL FILE FORMAT. Finally, you use the data source and the file format as parameters in the WITH clause of the CREATE EXTERNAL TABLE statement. So, in reality you are creating a pointer to the file that is mapped to a table structure that is queryable. It acts like a table, but it is not the same as a table created on a dedicated SQL pool. The other capability to call out is the Max query duration. Unlike dedicated SQL pools, which allow you to choose the performance level of the node, as shown in Table 3.8, serverless SQL pools manage the scaling for you. Cost management for serverless pools is managed by limiting the amount of data queried daily, weekly, and/or monthly. This is in contrast to dedicated pools, where you pay for the selected performance level.
TABLE 3.8 Dedicated SQL pool performance level
| Performance Level | Maximum nodes | Distributions | Memory |
| DW100c | 1 | 60 | 60 GB |
| DW300c | 1 | 60 | 180 GB |
| DW500c | 1 | 60 | 300 GB |
| DW1000c | 2 | 30 | 600 GB |
| DW1500c | 3 | 20 | 900 GB |
| DW2500c | 5 | 12 | 1,500 GB |
| DW5000c | 10 | 6 | 3,000 GB |
| DW7500c | 15 | 4 | 4,500 GB |
| DW10000c | 20 | 3 | 6,000 GB |
| DW15000c | 30 | 2 | 9,000 GB |
| DW30000c | 60 | 1 | 18,000 GB |
Notice in Table 3.8 that the ratios between maximum nodes and distributions conform to the law of 60. Using this table together with the knowledge of number of data rows can help you determine the optimal size. Remember that you need 1,000,000 rows of data per node to meet the requirement for performance boosting caching to kick in. If your distribution were 10,000,000 rows of data, which performance level would you choose? The maximum would be DW5000c, because you want to have 1,000,000 distributed across the nodes. Perhaps DW1500c or DW2500c are better choices to be certain you breach the threshold. But, like with all decisions, the choice is based on the scenario and how compute‐intense your queries are.