
What is a serving/data exploration layer? Don’t confuse it with something called the servicing layer, which is common in a service‐oriented architecture (SOA). For an illustration of the serving layer, see Figure 3.13. The serving layer is one component of a larger architecture that includes a speed layer and batch layer. The Big Data architecture pattern shown in Figure 3.13 is called lambda architecture. The purpose of the serving layer is to boost transformation of data so that consumers can query it in near real time or as fast as technically possible. It enables consumers to query data ingested through both a hot and cold path simultaneously.
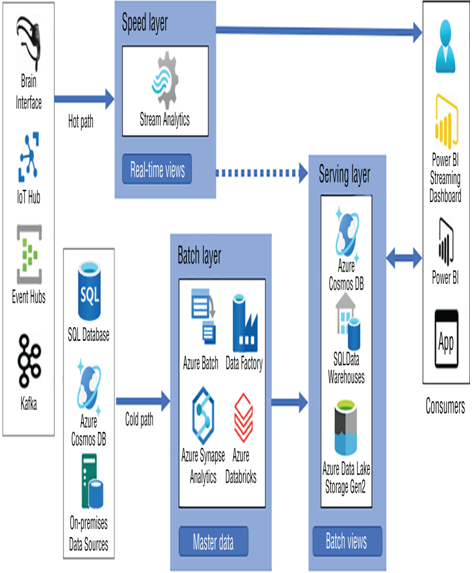
FIGUER 3.13 The lambda architecture serving layer
Notice that the Azure products Azure Cosmos DB, SQL Data Warehouse, and ADLS are represented as datastores in the serving layer. Data provided through the serving layer requires a place to be stored, and those are some relevant products to store them on. It is important, however, to recognize that the data stored in those products, in this context, is not canonical data. That means the data is not in its final state. Data in its final state would be of the highest formal quality necessary for complex analytic processing. The data in this state has a context bound to a specific purpose and can be deleted and regenerated at any time. The purpose again is to get the data from ingestion to a state of consumption quickly.
A new alternative to the lambda architecture is called kappa architecture. When you implement the lambda architecture, you will find some duplication of effort. The coded logic that transforms and moves data through the cold and hot path is often duplicated. In most cases, the coded logic in these two paths is not 100 percent identical, which means you must perform changes and testing on more than a single set of code. The kappa architecture removes the necessity of the serving layer altogether. It combines the cold and hot path into one and focuses on the real‐time views and master data for providing the optimized transformation of data from producers to consumers.
Design Star Schemas
A star schema is a fact table that is surrounded by multiple dimension tables. It resembles a star shape, as shown in Figure 3.14.
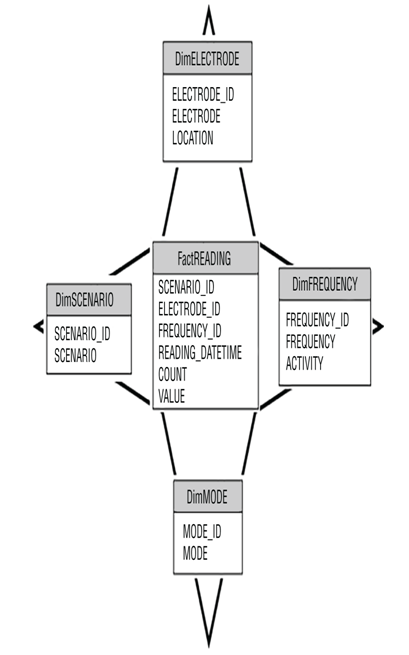
FIGUER 3.14 A relational star schema
A fact table is a table that holds the data that is used for your data analytics work. The table is specifically and optimally designed for read operations, in contrast to supporting write operations—for example, INSERT, UPDATE, and DELETE. A fact table is the opposite of a table you would find in an OLTP, OLAP, or HTAP environment, as those are optimized for write operations. The data stored on the FactREADING table would change when new data is added from other data sources. The frequency would be dictated by the business need.
Tables that have data that does not change often are called dimension tables. The data in the DimELECTRODE table, for example, would seldom change. That table contains data that represents a physical BCI and cannot be modified. The other Dim tables might change, but the expectation is that dimension tables, in general, contain data that will not change often. Data in a dimension table can also be used to filter data—for example, if you want to capture only data for a given electrode. You can use the data on the dimension table to find the value used to filter the data on the fact table.