
Before reading any further, ask yourself what an analytical store is. If you struggle for the answer, refer to Table 3.2, which provides the analytical datastores available in Azure, as well as the data model that works optimally with those products. Table 3.1 provides a list of different ingestion types mapped to the most suitable Azure data analytics product. The reason to call attention to the information in Table 3.1, which is focused on ingestion, is that you will notice that many of the same analytical datastores in Table 3.2 are also optimal for certain types of ingestion. Combine those two tables with Table 3.3, and you can narrow down which Azure data analytics product to use in your scenario.
Consider a few additional scenarios using the information you have learned in this chapter. For example, does your data analytics solution need to supply data to a hot path serving layer? Or does your solution require massively parallel processing (MPP)? Table 3.6 provides some information about these options, which, when used in addition to the other tables, should be very helpful in picking the necessary analytical store for your solution.
TABLE 3.6 Hot path serving layer and MPP products
| Product | Hot path serving | Massively parallel processing (MPP) |
| Azure Synapse SQL pool | Yes | Yes |
| Azure Synapse Spark pool | Yes | Yes |
| Azure Data Explorer | Yes | Yes |
| Azure Cosmos DB | Yes | No |
| Azure Analysis Services | No | Yes |
An analytical store is a place where you store data used by your data analytics solutions, from end to end. An analytical store houses data regardless of the Big Data stage (as illustrated by Figure 2.30) and regardless of the data landing zone (as identified in Table 3.4).
Design Metastores in Azure Synapse Analytics and Azure Databricks
A metastore is a place to store metadata. Earlier in this chapter you learned about the metadata associated with files, such as creation date, size, and update date. Metadata is also available for the objects stored within a database, for example, views, relationships, schemas, and tables. You can access the metadata for your database objects in the metastore. There are numerous tools that will graphically illustrate the objects in a database, including Azure Data Studio and Microsoft SQL Server Management Studio. However, not all DBMSs or analytical datastores have such features. Querying the metastore is the only means for discovering the existence and structure of tables. Metastores also help you begin to visualize database details that help you figure out what is contained in the database and how the data can be used. Remember that data is simply organized characters in a flat file, managed by a DBMS. Without any means for analyzing the data and the structure of the data in a file, it would be hard to get value from it. Queries such as select * from sys.tables or describe formatted <tableName> will render table and schema information on a SQL database.
Since Apache Spark workloads are most often concentrated on data files, there needs to be some kind of mechanism for creating virtual databases and tables on top of your file data. The product that stores metadata and creates this virtualization is called Apache Hive. The database and table listings shown in Figure 3.21 are made possible by the metadata stored in Hive. Azure Databricks, for example, uses Hive to build the content for the Data menu item, as shown in Figure 3.21.
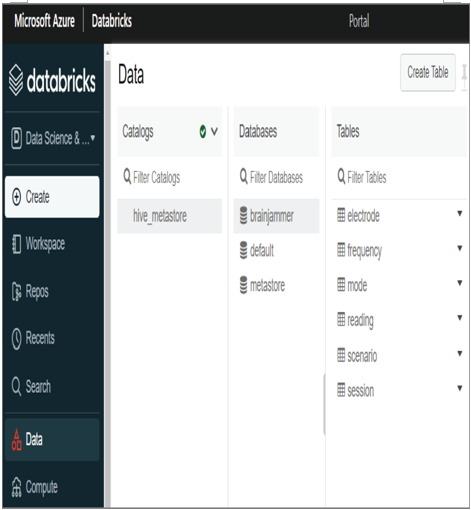
FIGUER 3.21 A Hive metadata metastore
The list of databases and tables are retrieved from the default file‐based Hive metastore loaded on a data share. See the next section for more about this Hive metastore using Azure Databricks.