
- Navigate to the Azure Data Factory you created in Exercise 3.10, and then click the Open link on the Overview blade in the Open Azure Data Factory Studio tile.
- Select the Author hub ➢ hover over Pipeline and click the ellipse (…) ➢ click new pipeline ➢ expand the Move & Transform group ➢ drag and drop Copy Data into the workspace ➢ on the General tab, provide a name ➢ select the Source tab ➢ select the dataset you created in Exercise 3.12 from the Source Dataset drop‐down box ➢ and then click the Sink tab.
- Click + New next to the Sink Dataset drop‐down box ➢ select Azure Data Lake Storage Gen2 ➢ click Continue ➢ select Parquet ➢ click Continue ➢ provide a name ➢ select + New from the Linked Service drop‐down ➢ create a linked service to the ADLS container you created in Exercise 3.1 ➢ in the Set Properties window, select the folder icon in the File Path section (interactive authoring must be enabled and running) ➢ select the path where you want to store the file ➢ do not select a file ➢ enter a file name into the text box that contains File (I used ALL_SCENARIO_ELECTRODE_FREQUENCY_VALUE.parquet) ➢ select the None radio button ➢ and then click OK.
- Click the Debug button at the top of the workspace window ➢ wait ➢ watch the Status value on the Output tab until you see Succeeded ➢ and then navigate to the ADLS container in the Azure portal. You will see the Parquet file.
Power Query
This option bears a great resemblance to what you might find in Power BI. The same engine that runs Power BI likely runs the Power Query plug‐in. The feature provides an interface for viewing the data from a selected dataset. You can then run through some transformation ideas and see how the data will look once the change is applied. When you are happy with the outcome, you can use the Power Query feature as an activity in the pipeline.
Azure Databricks
Databricks is the most used Big Data analytics platform currently available for extract, transform, and load (ETL) or extract, load, and transform (ELT) transformations and insights gathering. Since Databricks is based on open‐source principles, companies like Microsoft can branch the product and make their own version of it. That version is Azure Databricks. Databricks itself is based on the Apache Spark ecosystem, which is made up of four primary components: Spark SQL + DataFrames, Streaming, Machine Learning (MLlib), and Graph Computation. The platform also supports languages like R, SQL, Python, Scale, and Java. Azure Databricks provides an interface for provisioning, configuring, and executing your data analytics on a mega scale. Figure 3.64 illustrates the Azure Databricks platform.
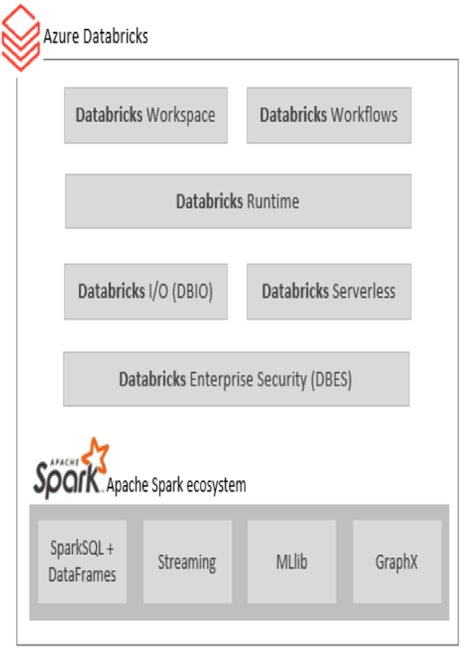
FIGUER 3.64 The Azure Databricks platform
As previously mentioned, a workspace is a place where you and your team perform the actions required to create and maintain a data analytics solution. A Databricks workflow is like a pipeline, in that it has numerous activities to ingest and transform data. The Databricks runtime is the code and process that manages the health and execution of the workflows. Runtimes are the brains or the guts of a platform—where the magic happens. The Databricks I/O (DBIO) is a system driver that optimizes the reading and writing of files to disk. For example, when you use the createDataFrame() method along with the Databricks File System (DBFS), DBIO will be engaged to help perform the loading and any writing of the data file. From a Databricks Serverless perspective, you know how the power of scaling increases performance and controls costs. It is possible to scale out to as many as 2,000 nodes (aka instances) to execute your data ingestion and transformations. This would only be possible in the cloud because the cost of having 2,000 servers, often sitting idle, is not cost‐effective. Instead, serverless allows you to provision compute power when you need it, pay for that, and then deprovision the servers when not needed. You do not pay for compute that is not used. Encryption, identity management, RBAC, compliance, and governance are all components of Databricks Enterprise Security (DBES). As you work through Exercise 3.14 and the following section, attempt to discover the security‐related options, which are part of DBES.