
- Navigate to the Azure Data Factory you created in Exercise 3.10, and then click the Open link on the Overview blade in the Open Azure Data Factory Studio tile.
- Select the Author hub ➢ hover over Dataset and click the ellipse (…) ➢ click New Dataset ➢ select Azure File Storage ➢ select Excel ➢ click Continue ➢ enter a name ➢ select the linked service you created in Exercise 3.11 ➢ click the folder icon at the end of File path ➢ navigate to and select the ALL_SCENARIO_ELECTRODE_FREQUENCY_VALUE.xlsx file you uploaded in Exercise 3.9 ➢ click OK ➢ select READINGS from the Sheet Name drop‐down box ➢ check the First Row as Header check box ➢ select the None radio button ➢ and then click OK.
- Click the Test Connection link on the Dataset page, and then click the Preview Data link, which renders something similar to Figure 3.63.
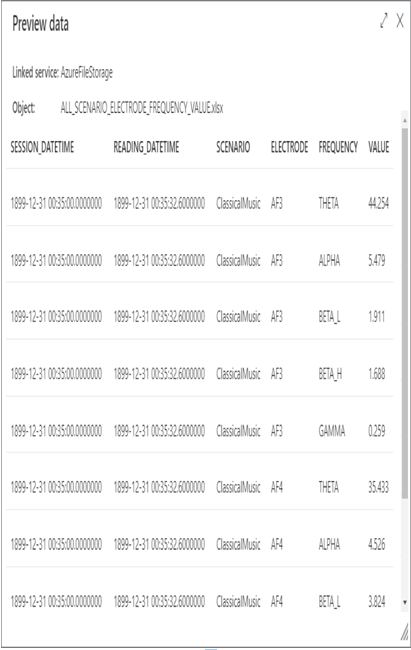
FIGUER 3.63 Azure Data Factory Author dataset
A dataset is used as parameters for the source and sink configuration in a pipeline that contains a Copy Data activity.
Pipeline
The Azure Data Factory pipeline user interface is almost identical to the one in Azure Synapse Analytics. Pipelines are groups of activities that can ingest and transform data from many sources and formats. A dataset is required as an input for both the source and sink (destination) of the data. In Exercise 3.13, you use the dataset created in Exercise 3.12 to convert the data stored in XLSX into Parquet using the Copy data activity in a pipeline.