
- Log in to the Azure portal at https://portal.azure.com ➢ navigate to the Azure Synapse Analytics workspace you created in Exercise 3.3. On the Overview blade click the Open link in the Open Synapse Studio tile ➢ select the Data hub item ➢ select the Workspace tab ➢ click the + to the right of Data ➢ select Connect to External Data ➢ select Azure Cosmos DB (SQL API) ➢ and then click Continue.
- Name the connection ➢ provide a description ➢ enable interactive authoring by hovering over the information icon next to the item ➢ select Edit Interactive Authoring ➢ enable it ➢ click Apply ➢ and then choose the Azure Cosmos DB by selecting the subscription, Azure Cosmos DB account, and database name. Leave everything else. The configuration should be similar to Figure 3.50. Click Commit.
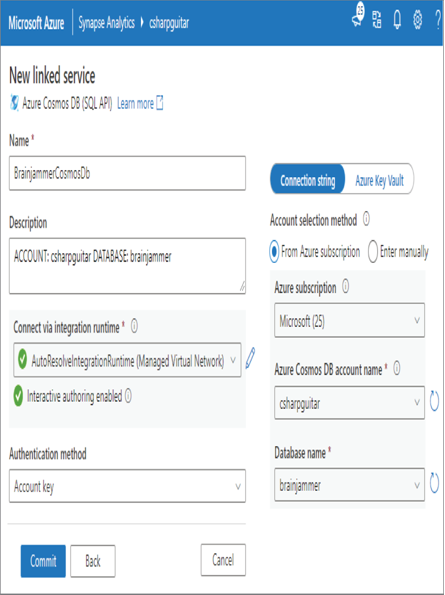
FIGUER 3.50 Azure Synapse Analytics Data connect Azure Cosmos DB
- Once the connection is rendered on the Linked tab, expand Azure Cosmos DB ➢ expand the connection you just created ➢ hover over the Container (in this case, sessions) ➢ click the ellipse (…) ➢ select New SQL Script ➢ click Select TOP 100 Rows ➢ consider opening another browser tab and navigate to your Azure Cosmos DB in the Azure Portal ➢ choose the Keys navigation menu option ➢ copy the PRIMARY KEY ➢ use this key as the SECRET ➢ use the Azure Cosmos DB account name as the SERVER_CREDENTIAL (it is prepopulated in the system generated SQL query) ➢ and then place the following snippet at the top of the generated SQL so that it runs first:
CREATE CREDENTIAL WITH IDENTITY = ‘SHARED ACCESS SIGNATURE’, SECRET = ” GO - Click Run. The selected results are rendered into the Results window.
You can use this feature to try out queries and discover what data you have in the container. Then use those findings to perform data transformations or gather business insights.
Integration Dataset
The purpose of integration datasets is in its name. Integration datasets provide an interface to easily integrate existing datasets into the Azure Synapse Analytics workspace. Once the data is placed onto a node accessible on the workspace by the IR, computations can be performed on it. A dataset is a collection of data. Consider that you have a relational database with many tables that contain both relevant and irrelevant information. Instead of copying over the entire database, you can extract a dataset of just the information you need. You might even want to create numerous datasets from a single data source, depending on what data is present and the objectives of your data analytics solution. Figure 3.51 illustrates where a dataset fits into the overall data ingestion scheme.
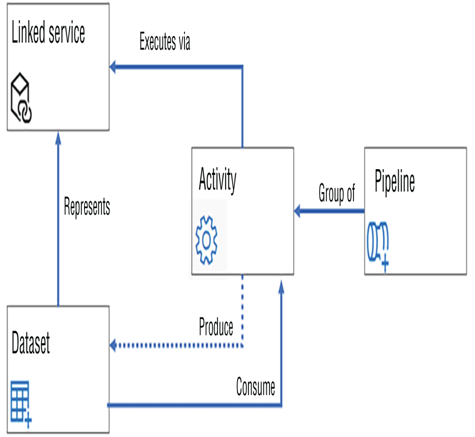
FIGUER 3.51 How a dataset fits in the data ingestion scheme
A linked service is required to extract data from a storage container to populate the dataset when instantiated. The dataset is a representation of a collection of data located on the targeted linked service. A dataset is not concrete, in that it is a representation of data collected from a file, table, or view, for example. A pipeline consists of a group of activities, where an activity can be the execution of a stored procedure, a copy/move process, or the triggering of a batch process, to name a few. As shown in Figure 3.51, the activity is gathering the data from the linked service, placing it into the dataset, and then performing any additional activity on it, as required. To learn more about the configuration of an integration dataset, complete Exercise 3.9.