
Azure Databricks generates a metastore by default with the provisioning of a cluster. After creating a cluster, you can query the metastore. Doing so produces a visualization of any table. Figure 3.22 illustrates the retrieval from the metastore using the show tables in <databaseName> command. Executing the command lists all the tables in the targeted database.
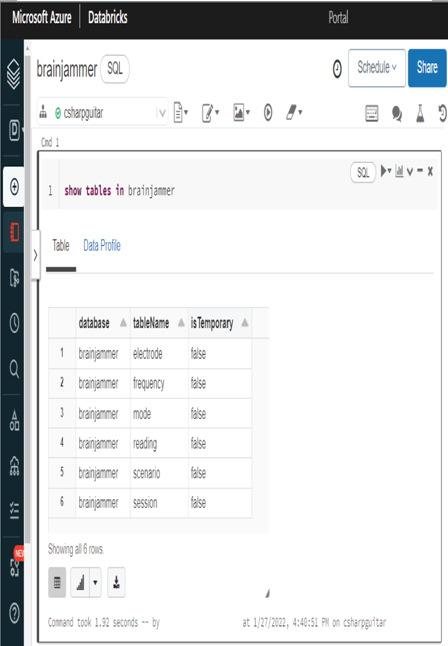
FIGUER 3.22 A Hive metadata metastore database
To show the details of a table, use the command describe formatted <databaseName>.<tableName>, as shown in Figure 3.23. Notice that the table column names and data types are rendered as well as other metadata, such as the location, owner, and provider.
The metastore is file‐based by default and accessible during and from your Azure Databricks session. Other individuals who use the same workspace will not have access by default. The default Hive metastore is not optimal for team or enterprise Big Data analytics. Instead, you should create an external metastore that runs in a database such as Azure SQL or an Azure Database for MySQL. This way, other team members can discover these tables and use them in their analytics efforts. Creating an external Apache Hive metastore makes its contents more discoverable and scalable for large data analytics workloads.
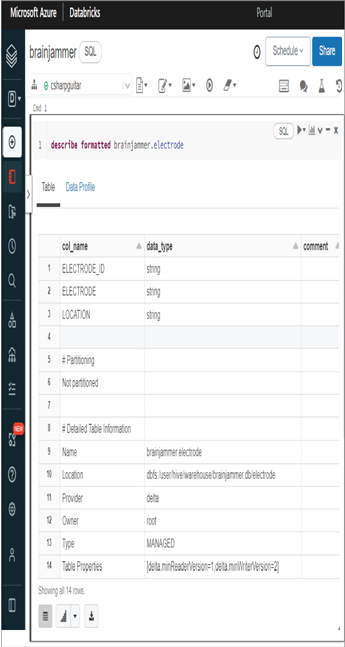
FIGUER 3.23 A Hive metadata metastore table
Azure Synapse Analytics
Azure Synapse Analytics includes support for accessing an Apache Hive metastore. You can access a Hive metastore by using a Spark pool.
Spark Pool
After learning in Exercise 3.4 how to configure a linked service, you will be able to execute the query shown in Figure 3.24.
The spark.sql queries are similar to those shown in the previous figures concerning metastores. The output of the queries renders the list of databases found in the namespace and the tables within the targeted database.
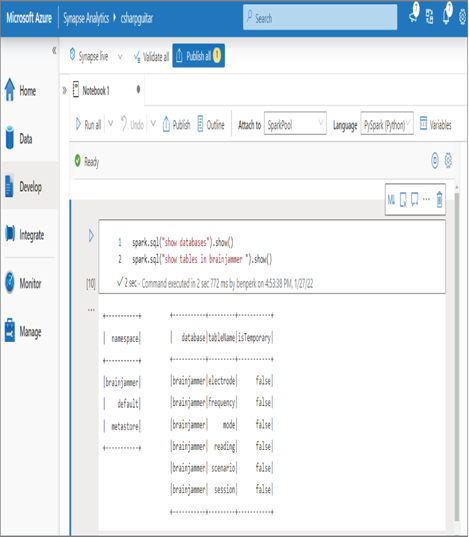
FIGUER 3.24 A Hive metadata metastore spark pool
The metastore in your chosen external database must exist before you can perform queries on it. Create the external metastore first, and then you can access it from the Spark pool.
The metadata is retrieved from the same data source when running on an Azure Synapse Analytics Spark pool as when running on an Azure Databricks cluster. This is true when both the Azure Databricks cluster and the Spark pool have been configured to do so. This will become clearer after you complete Exercise 3.4 and Exercise 3.14.
SQL Pool
You also can query metadata in a SQL database, as shown in Figure 3.25.
You can discover which tables are available on a targeted database by selecting the list of databases and tables from the sys schema. It is possible to query files on a SQL pool; however, this most likely will not be on the exam, because that kind of analytics is mostly approached using Spark pools.
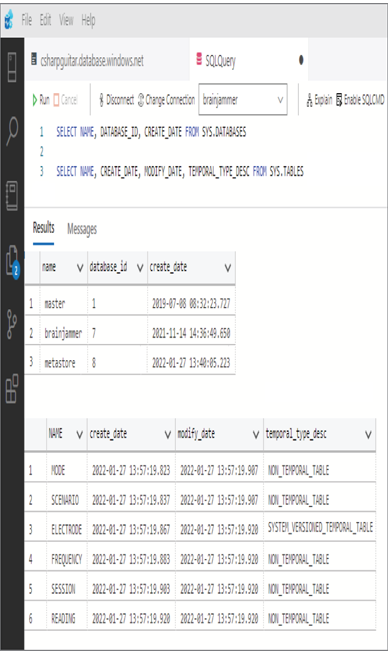
FIGUER 3.25 Querying metadata in a SQL database