
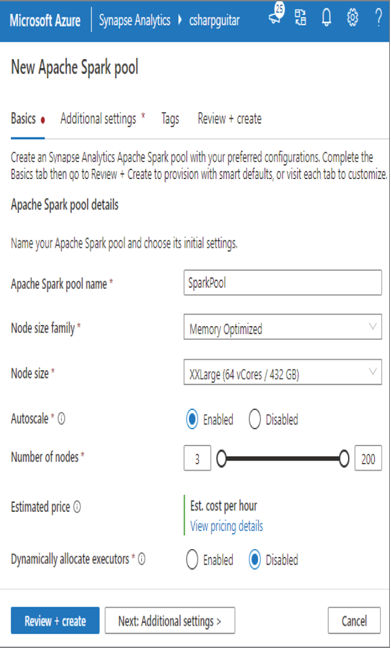
An Apache Spark pool is the compute node that will execute the queries you write to pull data from, for example, Parquet files. You can provision a Spark pool from numerous locations. One such place is from the Manage page in Azure Synapse Analytics Studio. After clicking the Manage hub option, select Apache Spark pools. The Basics tab is rendered, as shown in Figure 3.29.
This is where you can name the Spark pool, choose the node size, configure autoscaling, and more. Currently, the only selectable value from the Node Size Family drop‐down is Memory Optimized. Perhaps Compute Optimized is coming at some point in the future. The options found in the Node Size drop‐down are provided in Table 3.9.
TABLE 3.9 Spark pool node sizes
| Size | vCores | Memory |
| Small | 4 | 32 GB |
| Medium | 8 | 64 GB |
| Large | 16 | 128 GB |
| XLarge | 32 | 256 GB |
| XXLarge | 64 | 432 GB |
FIGUER 3.29 Azure Synapse Analytics Apache Spark pool Basics tab
The great part about autoscaling is that the logic and algorithms that determine when the processing of data analytic queries require more compute is provided to you. You do not need to worry about it. Scaling is targeted toward CPU and memory consumption, but there are other proprietary checks that make scaling work very well. In addition to provisioning more nodes when required, autoscaling also decommissions nodes when they are no longer required. This saves you a lot of money, because you are allocated only the compute power you need and not more. It used to be that you needed to purchase your own hardware to manage queries, and those servers often were idle, which was not an optimal use of resources. This is one reason running Big Data analysis in the cloud is so popular. Provisioning required compute power on demand and then decommissioning it when complete is very cost effective. You might want to limit the maximum number of nodes that the Spark pool expands to. This can help control costs. The ability to dynamically allocate executors lets you scale in and out across the different stages of the Spark jobs you run on the node.
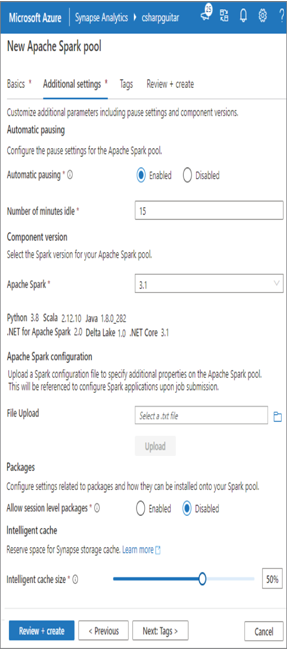
Next, you can navigate to the Additional Settings tab (Figure 3.30). It is a good idea to enable Automatic Pausing and then set the Number of Minutes Idle, which is used to shut down the node. This will save you money, as you are charged while the node is provisioned even if it is not doing anything. The default is to have Automatic Pausing enabled in 15 minutes. That means if you do not use the node in 15 minutes, it is shut down. The configuration of the node remains, so when you are ready to run some work again after the 15‐minute timeframe, a new node is provisioned using the created configuration, and you are ready to go in about three minutes. At the moment, the supported versions of Apache Spark are 3.1 and 2.4. As shown in Table 3.10, those versions also come with different component versions.
TABLE 3.10 Apache Spark components
| Component | Apache Spark 3.1 | Apache Spark 2.4 |
| Python | 3.8 | 3.6 |
| Scala | 2.12.10 | 2.11.12 |
| Java | 1.0.8_282 | 1.8.0_272 |
| .NET Core | 3.1 | 3.1 |
| .NET for Apache Spark | 2.0 | 1.0 |
| Delta Lake | 1.0 | 0.6 |
FIGUER 3.30 Azure Synapse Analytics Apache Spark pool Additional Settings tab
If you need to perform any Spark configurations on the nodes at startup (while booting), the Apache Spark Configuration section is the place to add them. For example, you can add the required configuration to create or bind to an external Hive metastore. Save the necessary configurations to a .txt file and upload it. If you need to install packages or code libraries at the session level, select the Enabled radio button in the Allow Session Level Packages section. Remember that your sessions have a context isolated to the work you are specifically doing in Azure Synapse Analytics Studio. The session is terminated when you log out of the workspace. If you need the configuration to be accessible to more people and remain static even after you log off, then use the configuration option in the File Upload option. You will also need to grant others access to the resources. (Those steps are coming in later chapters, Chapter 8 specifically.) The Intelligent Cache Size slider lets you cache files read from ADLS Gen 2. A value of zero disables the cache. The total amount of storage for cache depends on the node size you chose (refer to Table 3.9). Because cache is stored in memory, in a node with a total of 32 GB, selecting 50% on the slider means that 16 GB of file data can be stored in memory.